|
This page last changed on Mar 13, 2008.
How To Develop Good XQSEs
The XQuery Scripting Extension (XQSE) language is an XQuery extension that BEA has newly introduced in ALDSP 3. The availability of XQSE opens doors to many places one could not easily go to in previous releases of ALDSP, at least not without leaving XQuery and writing custom Java code. The purpose of this "how to" guide is to show its readers some of what's now possible in ALDSP thanks to XQSE. It is a companion to the more formal XQSE Language Reference. TopicsUseful References
Not Just How To, But When and Why, TooIntroductionIn addition, this guide aims to provide its readers with insight into when, and why, XQSE should be used to write a given data service operation instead of writing it in XQuery (or Java). To that end, this guide is organized as a guided tour of a series of "typical XQSEs" — it presents a series of use cases to which XQSE is the answer, and it briefly explains how and why XQSE and its various features are "the right way" to address each of the use cases. For readers' convenience and entertainment, all of the material presented here is also available as an importable ALDSP 3.0 data space project. Before reading further, you should stop here and import that project. The underlying relational data sources for the XQSE-How-To project are all prepackaged with ALDSP 3.0, so once you import it, you'll have everything that you will need to study our XQSEs and start making up some clever new XQSEs of your own. Having the Right MindsetBefore proceeding any further, hopefully you've noticed the best part of the language: its name. If you haven't already figured it out, XQSE is properly pronounced "excuse", and XQSEs are "excuses". When your boss asks you if you've got those critical data services ready for him or her yet, you can now answer "Well, no, not yet, boss, but I've come up with some really good XQSEs!" Is this a great language, or what...? Understanding the XQSE-How-To ProjectThe XQSE-How-To project is based on a relational database-based scenario involving the time-worn example of employees and departments. It involves three tables, including a pair of related tables EMP and DEPT from one hypothetical data source (drawn from the sample Pointbase JDBC data source dspSamplesDataSource) and a third table EMP2 from a second hypothetical data source (from the Pointbase JDBC data source dspSamplesDataSource1).
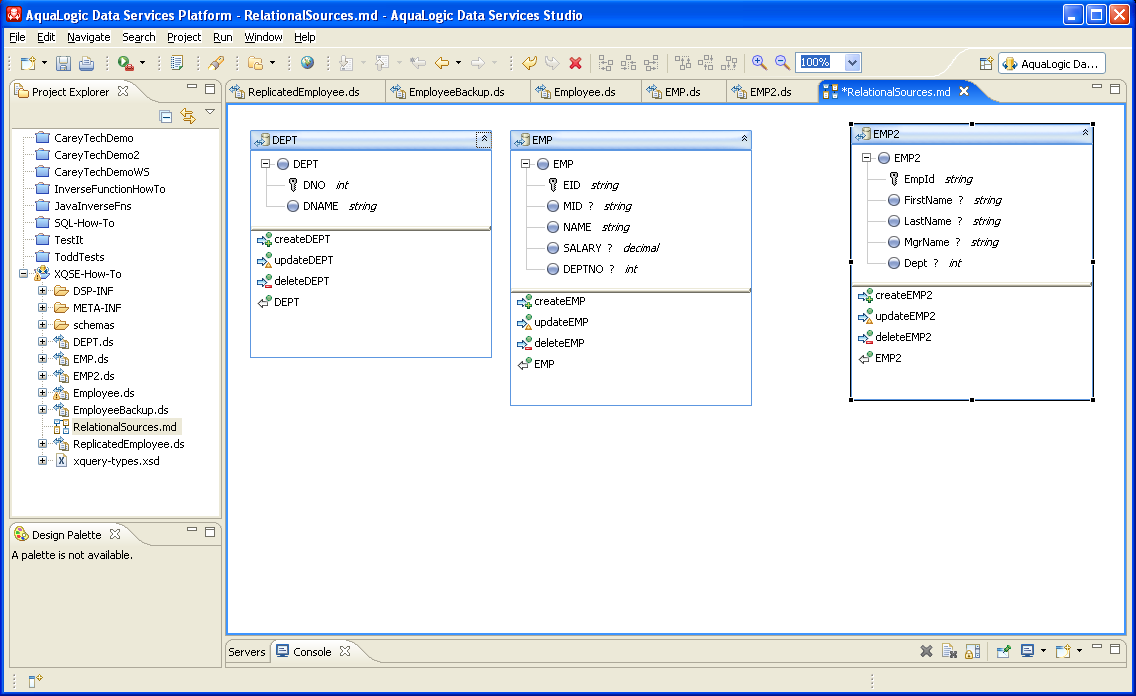
The EMP/DEPT tables include information about who works for who, in which department, and earning how much. The management hierarchy sets the stage for showing how XQSE can help with ALDSP use cases requiring data-dependent recursion or iteration. EMP will also be used to show how XQSE can be used to check and enforce business rules on updates. The EMP2 table has much of the same information as EMP, but it represents the information in a somewhat different form — and hypothetically in a different geographical location as well — thereby setting the stage for showing how XQSE can help with transformation- and replication-related use cases. This will provide an opportunity to further show how XQSE can be used to express custom update-related logic, both for bulk updates and incremental updates, as well as showing a bit about exception handling in XQSE. Shown below for reference are the DDL statements used to create and populate the three sample tables. All three live in one Pointbase database that is then presented to ALDSP via several different JDBC data sources (to provide a way to simulate a distributed database environment, as each JDBC data source is handled as a different relational data source by ALDSP). CREATE SCHEMA EMP_DEMO; CREATE TABLE EMP_DEMO.EMP ( EID VARCHAR(8) NOT NULL, MID VARCHAR(8), NAME VARCHAR(32) NOT NULL, SALARY DECIMAL(10,2), DEPTNO INTEGER ); ALTER TABLE EMP_DEMO.EMP ADD CONSTRAINT EMP_PK PRIMARY KEY (EID); INSERT INTO EMP_DEMO.EMP ( EID, NAME, SALARY, DEPTNO ) VALUES( 'EMP1', 'Charlie Chairman', 1250000.00, 10 ); INSERT INTO EMP_DEMO.EMP ( EID, NAME, SALARY, DEPTNO, MID ) VALUES( 'EMP2', 'Dave Divisionhead', 275000.00, 10, 'EMP1' ); INSERT INTO EMP_DEMO.EMP ( EID, NAME, SALARY, DEPTNO, MID ) VALUES( 'EMP3', 'Suzy Supervisor', 250000.00, 10, 'EMP1' ); INSERT INTO EMP_DEMO.EMP ( EID, NAME, SALARY, DEPTNO, MID ) VALUES( 'EMP4', 'Denise Departmenthead', 180000.00, 20, 'EMP2' ); INSERT INTO EMP_DEMO.EMP ( EID, NAME, SALARY, DEPTNO, MID ) VALUES( 'EMP5', 'Alfred Architect', 175000.00, 20, 'EMP2' ); INSERT INTO EMP_DEMO.EMP ( EID, NAME, SALARY, DEPTNO, MID ) VALUES( 'EMP6', 'Larry Leafnode', 95000.00, 20, 'EMP3' ); INSERT INTO EMP_DEMO.EMP ( EID, NAME, SALARY, DEPTNO, MID ) VALUES( 'EMP7', 'Emily Engineer', 125000.00, 30, 'EMP3' ); INSERT INTO EMP_DEMO.EMP ( EID, NAME, SALARY, DEPTNO, MID ) VALUES( 'EMP8', 'Gregory Groupleader', 145000.00, 30, 'EMP4' ); INSERT INTO EMP_DEMO.EMP ( EID, NAME, SALARY, DEPTNO, MID ) VALUES( 'EMP9', 'Peter Peon', 79000.00, 30, 'EMP8' ); CREATE TABLE EMP_DEMO.EMP2 ( EmpId VARCHAR(8) NOT NULL, FirstName VARCHAR(32), LastName VARCHAR(32), MgrName VARCHAR(32), Dept INTEGER ); ALTER TABLE EMP_DEMO.EMP2 ADD CONSTRAINT EMP2_PK PRIMARY KEY (EmpId); CREATE TABLE EMP_DEMO.DEPT ( DNO INTEGER NOT NULL, DNAME VARCHAR(32) NOT NULL ); ALTER TABLE EMP_DEMO.DEPT ADD CONSTRAINT DEPT_PK PRIMARY KEY (DNO); INSERT INTO EMP_DEMO.DEPT ( DNO, DNAME ) VALUES( 10, 'Administration' ); INSERT INTO EMP_DEMO.DEPT ( DNO, DNAME ) VALUES( 20, 'Engineering' ); INSERT INTO EMP_DEMO.DEPT ( DNO, DNAME ) VALUES( 30, 'Testing' ); ALTER TABLE EMP_DEMO.EMP ADD CONSTRAINT DEPT_FK FOREIGN KEY (DEPTNO) REFERENCES EMP_DEMO.DEPT; If you browse through the XQSE-How-To project using Data Services Studio Project Explorer, you will see that all three of these tables have been imported into the sample project as physical data services of the relational variety. The model diagram below (RelationalSources.md in the XQSE how-to sample project) summarizes these three physical relationally-based data services as seen by ALDSP.
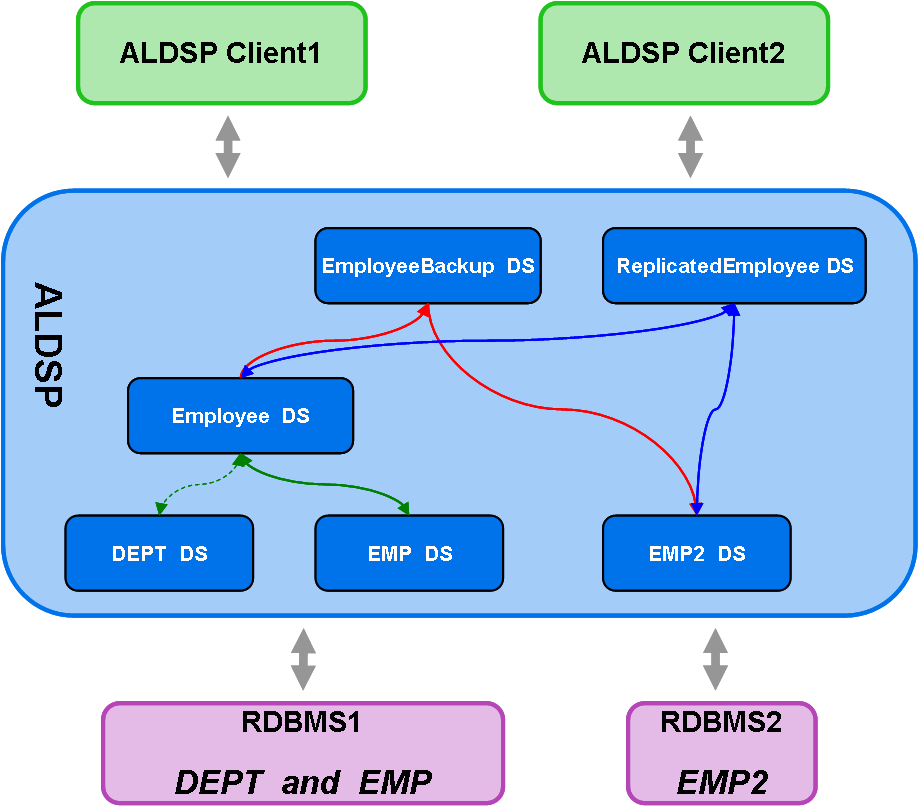
The following figure provides an overview of the XQSE How-To project's logical and physical data services and how they relate to one another. You will start off by creating a logical data service called Employee that provides a nice, cleaned-up view of the employee data from EMP (and potentially DEPT, though we will actually not use DEPT's content in this how-to). This data service will be used to illustrate several important read-only use cases where XQSE functions will nonetheless come to the rescue. The Employee data service will also be used to illustrate the use of XQSE to enforce business rules when data changes are being requested. The next step will involve the creation of a library data service called EmployeeBackup. This data service illustrates how XQSE can help with a "lightweight ETL" use case; the main operation provided by this data service will, when called, do a batch-replication of data from Employee into EMP2. Our final step will be to create another entity data service called ReplicatedEmployee. ReplicatedEmployee will show how XQSE can be used to customize update handling. This data service will use XQSE to keep the information in Employee and in EMP2 in sync.
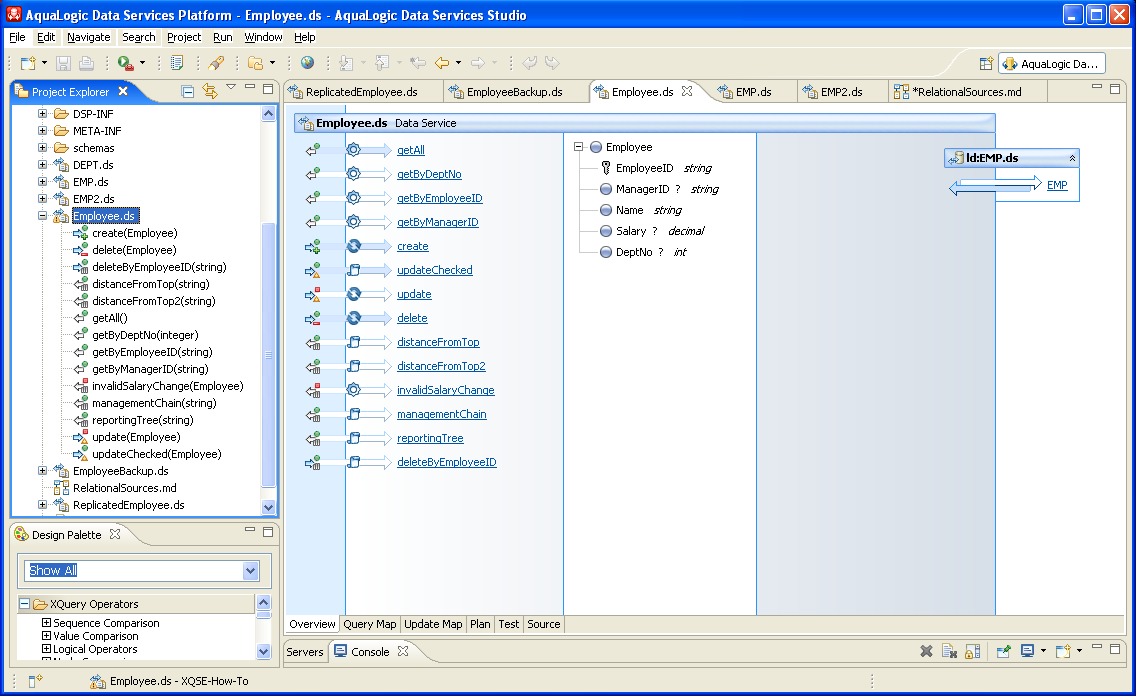
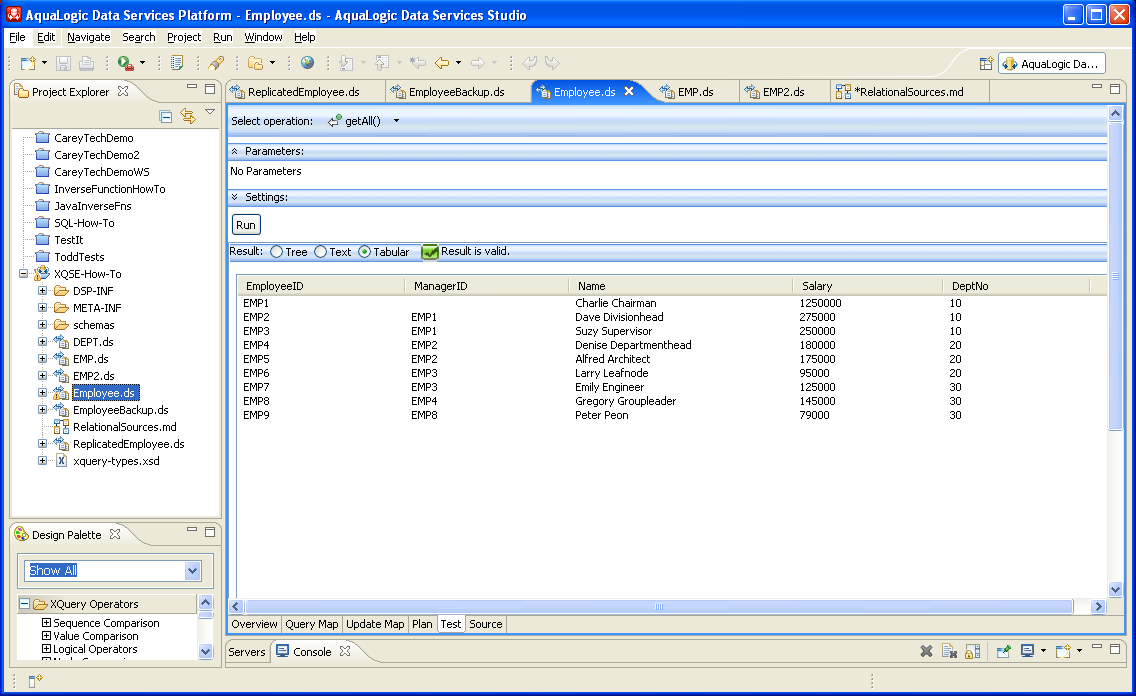
Employee.ds, Part One: How To Use XQSE FunctionsWhile XQSE is very important for customizing updates, it is also very useful for certain classes of read-only use cases. This is why ALDSP 3.0 supports XQSE functions as well as procedures, and that's where to begin the informal study of how to develop good XQSEs. The examples for this part of the study will all center around the logical data service Employee.ds in the XQSE How-To sample project. If you open the design view for the Employee data service, you will see the following:
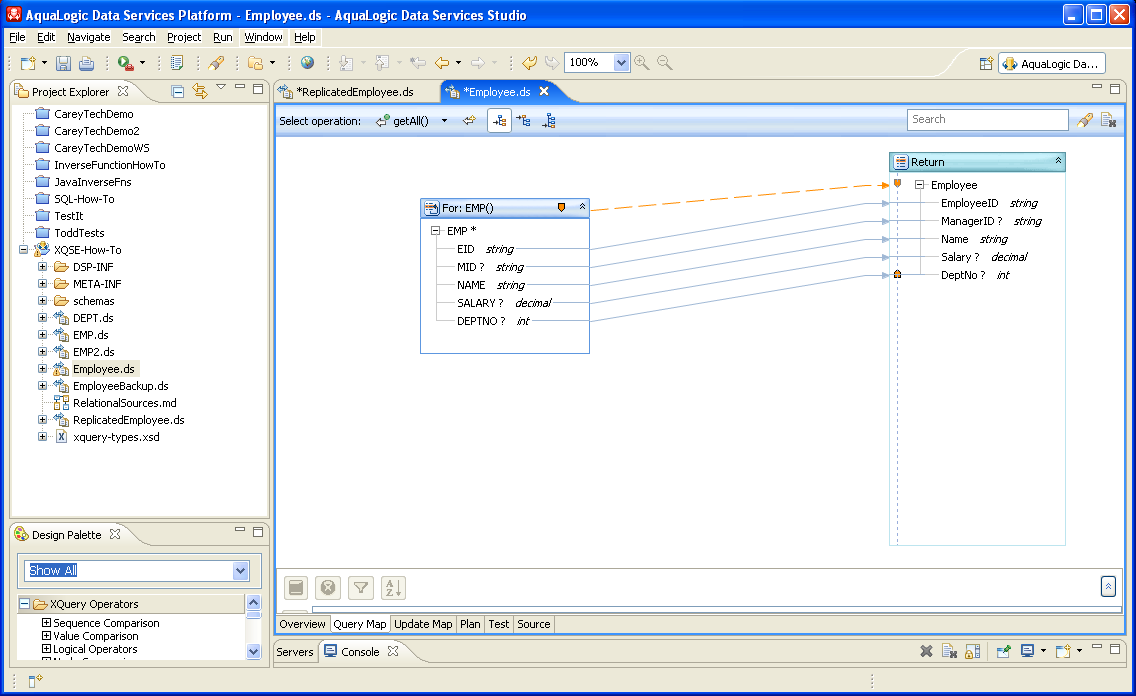
The Employee data service is a simple logical data service that slightly transforms the relational EMP data to make it "look nicer" for subsequent use. Its primary read function is very simple as a result, as you will see if you examine the query map view of the getAll() function of the Employee data service:
Before we dive into the details of the various XQSE functions of interest, you should try to get a feel for the Employee data that we will be working with. Here's what the getAll() function will return when you run it using your copy of the sample project:
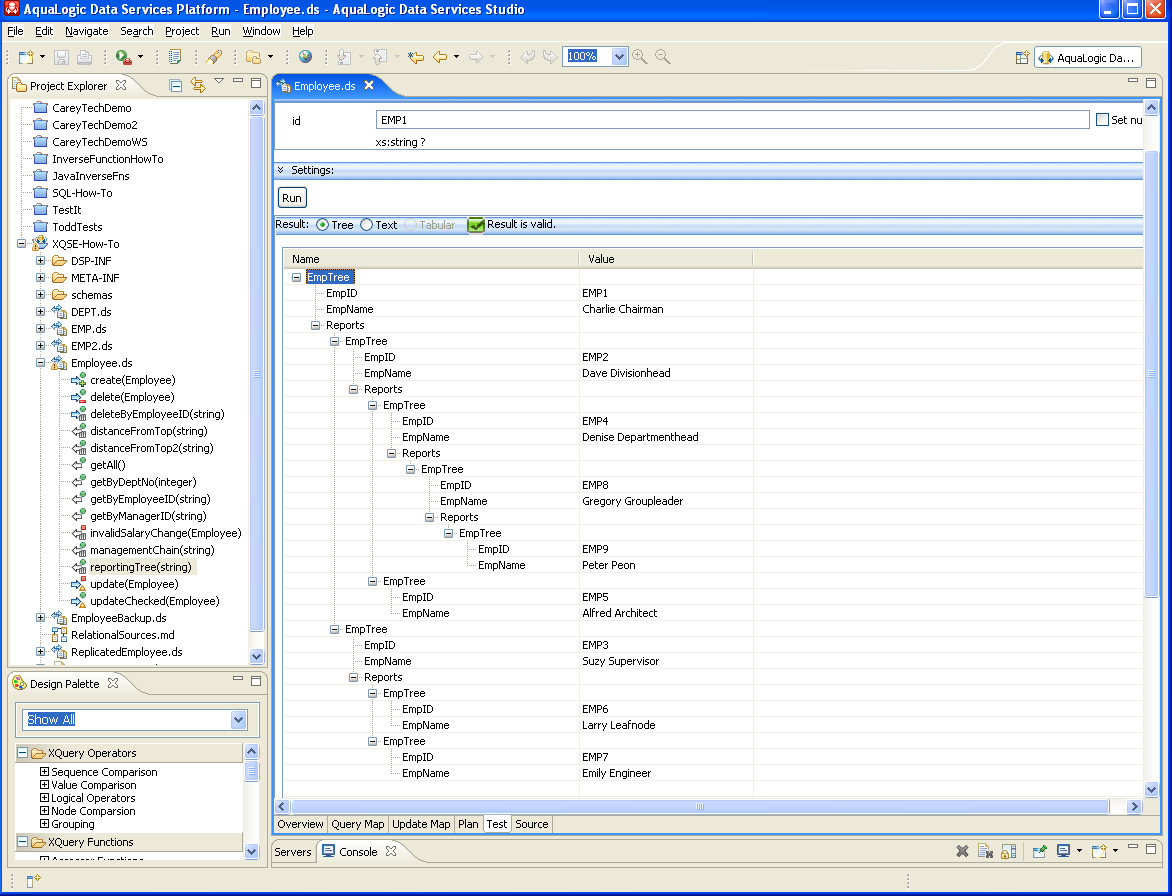
As you can see, the result is tabular, and it contains the employee ID, manager ID, employee name, salary, and department number for each of the employees of a small company. The CEO is the employee named Charlie Chairman, and you can tell that he's at the top of the food chain in the company because he has no manager. Who reports to who is encoded via the manager IDs in the database; Suzy Supervisor and Dave Divisionhead both report to Charlie, for example, as both have EMP1 (Charlie's employee ID) as their manager ID. Suzy's reports are Larry Leafnode and Emily Engineer, and so on. If you were to draw the full reporting tree including all of the employees, i.e., a tree with the employee IDs and names of everyone who reports either directly or indirectly to Charlie, you would end up with a picture like the following:
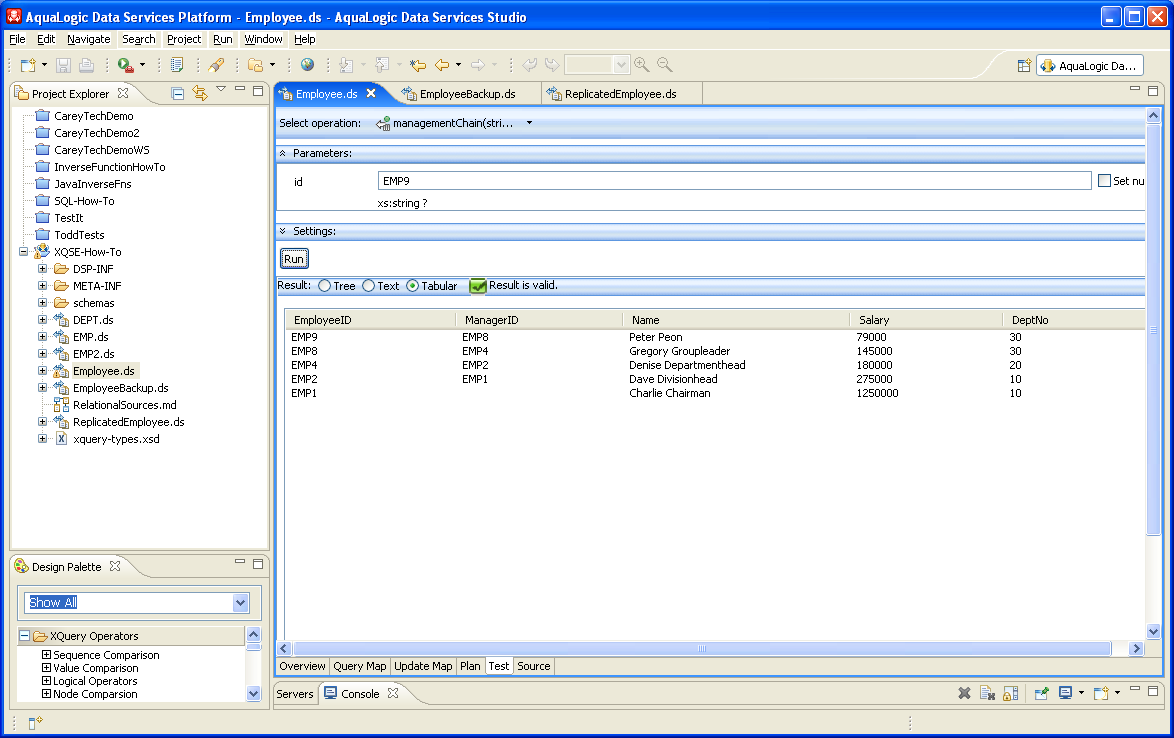
As you can see, this data is recursive in nature, making it challenging to deal with using just XQuery — particularly since ALDSP does not permit XQuery functions to be recursive. However, XQSE is more permissive in that regard. As you will soon see, dealing with this data is a perfect use case for XQSE, using either iteration or recursion. You can even use XQSE to generate a reporting tree like the one above! Basically, when you come across use cases that would demand recursion in XQuery, you've come across a good use case for XQSE. If your use case requires only tail recursion, then you can approach it using either iteration or recursion in XQSE (depending on what you find more natural, i.e., depending on how your brain happens to be wired). If your use case involves full recursion, like the reporting tree example, then you can use recursion in XQSE to tackle your problem. Let's now look at the examples of such use cases that are provided in the XQSE How-To sample project. First Some Helper FunctionsXQSE functions and procedures can utilize constructs from both XQSE and XQuery. For the use cases that you are about to examine, it will be helpful to have functions that get an Employee instance based on either an employee ID or a manager ID. The following XQuery source shows the XQuery definition of the Employee DS getAll() function as well as the use of this function to create the two XQuery helper functions, getByEmployeeID and getByManagerID, that we want for the XQSE use cases here. Hopefully it will be readily apparent what these functions do and how they do it. All three are categorized as read operations for the Employee data service, as all three return zero or more instances of an Employee. (::pragma function <f:function kind="read" visibility="public" isPrimary="true" xmlns:f="urn:annotations.ld.bea.com">::) declare function tns:getAll() as element(empl:Employee)* { for $EMP in emp:EMP() return <empl:Employee> <EmployeeID>{fn:data($EMP/EID)}</EmployeeID> <ManagerID?>{fn:data($EMP/MID)}</ManagerID> <Name>{fn:data($EMP/NAME)}</Name> <Salary?>{fn:data($EMP/SALARY)}</Salary> <DeptNo?>{fn:data($EMP/DEPTNO)}</DeptNo> </empl:Employee> }; (::pragma function <f:function kind="read" visibility="public" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com">::) declare function tns:getByEmployeeID($id as xs:string?) as element(empl:Employee)* { for $emp in tns:getAll() where $id eq $emp/EmployeeID return $emp }; (::pragma function <f:function kind="read" visibility="public" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com">::) declare function tns:getByManagerID($id as xs:string?) as element(empl:Employee)* { for $emp in tns:getAll() where $id eq $emp/ManagerID return $emp }; Read-Only Use Case 1: distanceFromTop (Iterative Solution)The first example to look at in the XQSE How-To sample project is the function distanceFromTop() in Employee.ds. The use case is simple: You know the employee ID for an employee, and you want to know how far down the corporate food chain that employee is — i.e., you want to know how far away a given employee is from the top of the company. Charlie Chairman's distanceFromTop is 0 — he's the CEO. For Suzy Supervisor, the answer is 1, as she's one step away from the top — she reports to Charlie — while for Emily Engineer, one of Suzy's reports, the answer is 2. You get the idea. But how can this be easily computed? With XQuery in ALDSP, this cannot be done, but with XQSE, it can. Open up the source view of Employee.ds for the distanceFromTop() function and you will see your first honest-to-goodness XQSE function: (::pragma function <f:function kind="library" visibility="public" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com">::) declare xqse function tns:distanceFromTop($id as xs:string?) as xs:integer? { declare $mgrCnt as xs:integer := 0; declare $curEmp as element(empl:Employee)? := tns:getByEmployeeID($id); declare $mgrId as xs:string? := fn:data($curEmp/ManagerID); if (fn:empty($curEmp)) then return value (); while (fn:not(fn:empty($mgrId))) { set $mgrCnt := $mgrCnt + 1; set $curEmp := tns:getByEmployeeID($mgrId); set $mgrId := fn:data($curEmp/ManagerID); }; return value ($mgrCnt); }; The function signature looks like an XQuery function, except with the modifier "xqse". The modifier tells ALDSP that this function's body will contain XQSE code, not just XQuery. It also tells ALDSP that this is a function, so it had better behave as such — having no side effects and so on. The function body starts by declaring three variables — mgrCnt, initially 0, for keeping track of the distance we are from the top; curEmp, initially the employee whose ID we have, for keeping track of the current employee under consideration; and mgrId, which holds the manager ID of the current employee. After defining and initializing these variables, the function uses an if-statement to immediately return the empty sequence (the XQuery and XQSE equivalent of a null) if there is no employee with the given ID. The function then uses a while-statement to walk from the current employee on up to the top of the corporate food chain. The while-loop will execute as long as the current employee is not yet the top employee, as indicated by the presence/absence of a manager ID. In each iteration, one is added to the distance traveled, you set the new current employee to be the old current employee's manager, and you extract the manager ID from the new current employee. Once you fall out of the loop, you've made it to the top — and the distance you've covered is recorded in mgrCnt — so the mgrCnt value is returned and you're done. By using XQSE, you can solve what would have been a difficult or impossible problem for earlier versions of ALDSP in just a handful of lines of extended XQuery code. Neat, huh? At this point, you should make sure you understand what you have seen so far. Take a short break, study the code one more time if need be, and in the Data Services Studio switch to Test view. What's the distanceFromTop for Peter Peon? Does the answer make sense? If you're challenged by what you're seen so far, hand-execute the XQSE code and see why the answer for Peter turns out to be 4. Read-Only Use Case 1: distanceFromTop2 (Recursive Solution)The distanceFromTop() function that you just saw used iteration to walk up the employee hierarchy, counting as it went. This is the most natural approach for many people. Another solution, however, would have been to use recursion: The distanceFromTop value for a given employee is zero if they are the CEO (i.e., if they have no manager), and it is simply their manager's distanceFromTop plus one otherwise. The XQSE function distanceFromTop2(), shown below and also provided in the Employee DS, solves the problem that way. This is an example of an XQSE function that employs tail recursion. Note the similarities between distanceFromTop2() and the previous XQSE function, distanceFromTop(). The key difference is that distanceFromTop2() doesn't loop — instead, it "repeats" its logic on the manager of the current employee by calling itself with the manager's employee ID. (::pragma function <f:function kind="library" visibility="public" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com">::) declare xqse function tns:distanceFromTop2($id as xs:string?) as xs:integer? { declare $curEmp as element(empl:Employee)? := tns:getByEmployeeID($id); declare $mgrId as xs:string? := fn:data($curEmp/ManagerID); if (fn:empty($curEmp)) then return value (); if (fn:not(fn:empty($mgrId))) then { set $curEmp := tns:getByEmployeeID($mgrId); set $mgrId := fn:data($curEmp/ManagerID); return value 1 + tns:distanceFromTop2($curEmp/EmployeeID); } else { return value 0; }; }; Read-Only Use Case 2: managementChainThe next XQSE function use case is similar to the first, but it shows how the data-handling power of XQuery and XQSE can allow something richer to be computed. The premise for this use case is the same, we have an employee ID in hand — but this time, you want to know details — you want to know who's in the management chain of the employee. (If the employee does something you don't like, you want to know where you can turn! The following XQSE code for the function managementChain(), available in the employee DS, computes this sequence. Structurally it is almost identical to distanceFromTop(). The main difference is that, instead of counting from zero, this function initializes the result sequence (empChain) to be the current employee and then keeps appending the new current employee to the end of the sequence as it loops its way up the management chain to the CEO. (::pragma function <f:function kind="library" visibility="public" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com"/>::) declare xqse function tns:managementChain($id as xs:string?) as element(empl:Employee)* { declare $curEmp as element(empl:Employee)? := tns:getByEmployeeID($id); declare $empChain as element(empl:Employee)* := $curEmp; declare $mgrId as xs:string? := fn:data($curEmp/ManagerID); while (fn:not(fn:empty($mgrId))) { set $curEmp := tns:getByEmployeeID($mgrId); set $empChain := ($empChain, $curEmp); set $mgrId := fn:data($curEmp/ManagerID); } return value ($empChain); }; If you understood distanceFromTop(), you will be able to quickly see how the logic for managementChain() works. Try running this XQSE function in the Test view. For Peter Peon, you should see:
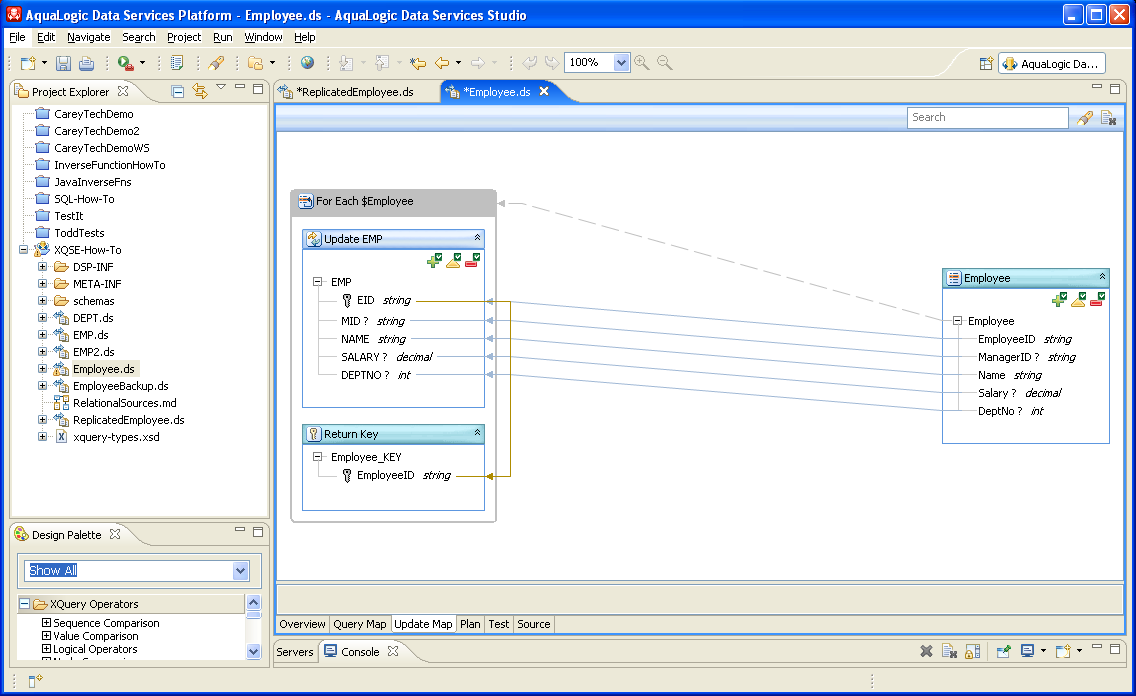
Read-Only Use Case 3: reportingTreeLet's close our discussion of XQSE functions with one more use case, a "recursive grand finale". Suppose that we wanted to compute the reporting tree for a given employee, the kind of tree that we discussed and showed earlier in the introduction to XQSE functions. The XQSE function reportingTree() in the Employee data service does exactly that (shown below). Notice how short and simple it is — XQSE can help you accomplish a lot with a small amount of code. Variable curEmp is the current employee, and variable reports is a list of the current employee's direct reports (obtained using the XQuery helper function that looks up employees by manager ID). What should the current employee's reporting tree look like? That's easy — it should contain their ID and name plus the reporting tree for each of their reports. This is exactly how the XQSE solution below solves the problem, using recursion to express the "plus the ..." part of this logic. Notice that the sequence of reports' reporting trees is computing using a small XQuery — "for $rep in $reports return tns:reportingTree($rep/EmployeeID)" — which demonstrates how XQuery and XQSE combine naturally to solve real problems. The XQSE function call from XQuery is perfectly legal because, at the end of the day, an XQSE function is just a function, and ALDSP XQuery queries are permitted to call XQSE functions anywhere they can call a function. (Factoid: This use case became a part of the XQSE How-To project because, on one of the days while it was being developed, someone posted a use case just like this on ldblazers!) (::pragma function <f:function kind="library" visibility="public" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com"/>::) declare xqse function tns:reportingTree($id as xs:string?) as element(EmpTree)? { declare $curEmp as element(empl:Employee)? := tns:getByEmployeeID($id); declare $reports as element(empl:Employee)* := tns:getByManagerID($id); declare $result as element(EmpTree)? := <EmpTree?> <EmpID?>{fn:data($curEmp/EmployeeID)}</EmpID> <EmpName?>{fn:data($curEmp/Name)}</EmpName> <Reports?>{ for $rep in $reports return tns:reportingTree($rep/EmployeeID) }</Reports> </EmpTree>; return value ($result); }; Employee.ds, Part Two: How To Use XQSE ProceduresOkay, you're off to a good start. You've seen how XQSE can be used to write functions, namely XQSE functions, that compute answers to use cases that were previously out of reach. In addition, you've now been exposed to a number of the features of the XQSE language including mutable variables, assignment statements, if-statements, and while-statements. Now it's time to look at the "bread & butter" use cases for XQSE — namely, use cases where update customization is needed. Prior to ALDSP 3.0, most custom update use cases required Java programming. Now a large class of such use cases can be handled using ALDSP's new Update Map editor. And what about the ones that can't? That's where XQSE comes in. In ALDSP 3.0, you can use XQSE to write your own update logic by writing your own custom create, insert, and update procedures and/or by writing library procedures with side effects that the consumers of your data services can then call. Your update procedures can either be used instead of the system's auto-generated update logic or in conjunction with it (by taking control, adding your logic, and then ultimately calling the system's own routines from within the bodies of yours). In this section of the XQSE How-To there are two representative examples involving update customization. The first will show how you can use XQSE to write your own procedures — much like a SQL stored procedure — with side effects. Applications can then be told about, and call, your new procedure. The other example will show how you can inject your own logic into the system's update automation machinery in order to enhance what happens when SDO-based updates are performed by client applications through ALDSP's Java or web service mediator APIs. Both of these examples are based on the Employee data service that we have been working with so far, so before going any further, let's look at the Update Map view for the Employee data service. Update Automation for the Employee DSIf you open the Update Map view of the Employee data service you will see the following:
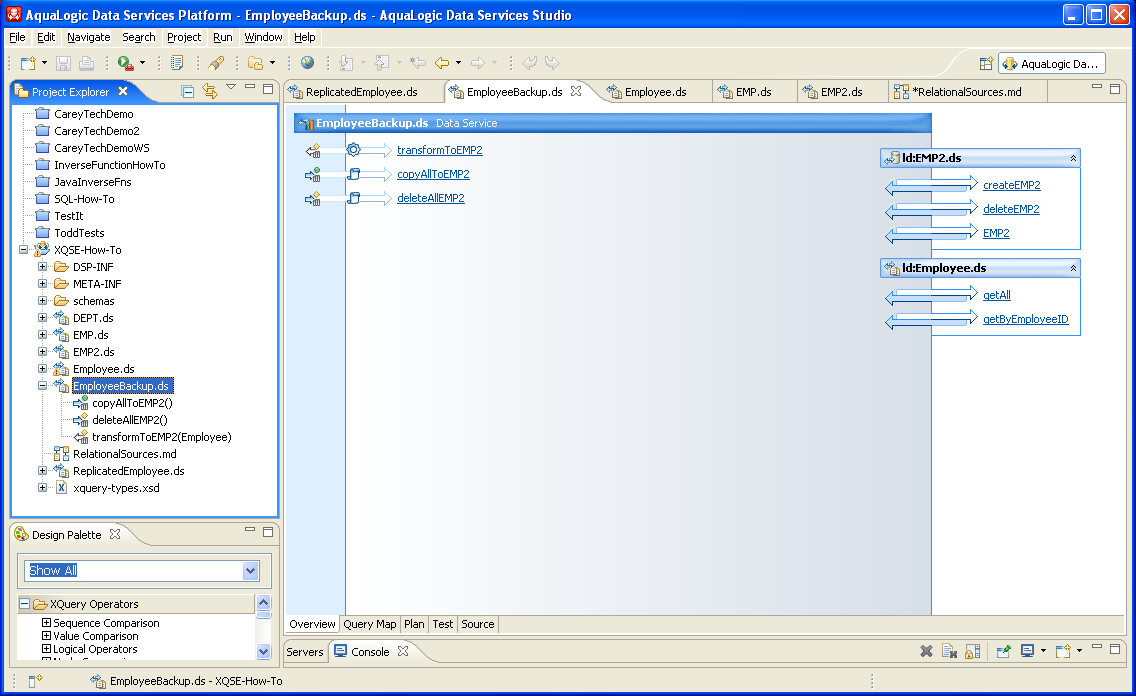
This update map was generated in the usual ALDSP 3.0 way. (This How-To assumes familiarity with ALDSP's 3 update map functionality. If you aren't so familiar with update maps see Managing Update Maps in the Data Services Developer's Guide. As you can see, ALDSP had no trouble generating a complete set of update machinery for the Employee data service. The primary read function (designated to be the getAll() function) does nothing more than some simple name remapping, which is easily reverse-engineered by ALDSP's update lineage analysis. As a result, create(), update(), and delete() procedures were all auto-generated without a hitch for the Employee data service. The Update Map view shows how data will move from an inserted, changed, or deleted Employee instance (shown on the right-hand side of the view) down to the underlying relationally-based EMP data service (on the left), as well as showing where the key returned by a create() call will come from (i.e., from the EID of EMP). The following source code snippet shows the operation signatures and pragmas for the resulting system-provided update procedures. First, notice that procedures insert() and delete() are public, while update() has been changed to be a private operation of the Employee data service (discussed below). For the same soon-to-be-covered reason, insert() and delete() are flagged as being primary (i.e., the designated handlers for the automation that processes SDO updates) while update() is not (isPrimary = "false"). Notice also that all three functions are external and implemented by ALDSP's auto-update machinery (i.e., their implementation type is "updateTemplate"). (::pragma function <f:function kind="update" visibility="private" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com"> <nonCacheable/><implementation><updateTemplate/></implementation> </f:function>::) declare procedure tns:update($arg as changed-element(empl:Employee)*) as empty() external; (::pragma function <f:function kind="create" visibility="public" isPrimary="true" xmlns:f="urn:annotations.ld.bea.com"> <nonCacheable/><implementation><updateTemplate/></implementation> </f:function>::) declare procedure tns:create($arg as element(empl:Employee)*) as element(empl:Employee_KEY)* external; (::pragma function <f:function kind="delete" visibility="public" isPrimary="true" xmlns:f="urn:annotations.ld.bea.com"> <nonCacheable/><implementation><updateTemplate/></implementation> </f:function>::) declare procedure tns:delete($arg as element(empl:Employee)*) as empty() external; Update Use Case 1: deleteByEmployeeIDSo far, so good — so what might you need to customize? Well, suppose that your client application developers want to be able to delete an Employee instance without having to fetch it from ALDSP first. Instead, they would like to be able to perform a "blind delete" operation based only on an employee ID. (I.e., no matter what data might be in the Employee instance at the moment — hence "blind" — they want the employee with that ID to be banished from the organization immediately.) We can meet this requirement by writing a library procedure in XQSE that looks up the employee with a given ID and then calls the system-generated delete operation. The following two-line procedure does exactly that: (::pragma function <f:function kind="library" visibility="public" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com"/>::) declare procedure tns:deleteByEmployeeID($id as xs:string?) as empty() { declare $emp as element(empl:Employee)? := tns:getByEmployeeID($id); tns:delete($emp); }; Update Use Case 2: updateCheckedAnother common reason for customizing updates is the need to condition the updates on not violating an application's business rules. For example, suppose that the little company whose data you've been looking at has a corporate rule against big raises and big paycuts: it's a violation of corporate policy to change an employee's salary by more than 10% at a time. Let's see how you can easily enforce such a business rule using a few lines of XQSE. First, you'll need a way to know whether or not an update is about to violate the 10% business rule. We can write a short boolean function in XQuery to do the required checking. For the 10% rule, the private function invalidSalary() in the Employee data service does this check. It takes as its argument an employee with changes — an instance of changed-element(Employee) — and it uses the ALDSP-provided node functions fn-bea:current-value() and fn-bea:old-value() to access the current and old values of the Employee instance that's being updated. By comparing the old and new salaries, it can detect attempts to violate the 10% rule and return true if the requested change is indeed invalid: (::pragma function <f:function kind="library" visibility="private" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com">::) declare function tns:invalidSalaryChange($emp as changed-element(empl:Employee)) as xs:boolean { let $newSalary := fn:data(fn-bea:current-value($emp)/Salary) let $oldSalary := fn:data(fn-bea:old-value($emp)/Salary) return (100.0 * fn:abs($newSalary - $oldSalary) div $oldSalary) gt 10.0 }; Given the XQuery function that encodes the business rule, it is now easy to use XQSE to enforce the rule. The following XQSE function, updateChecked(), has the same signature as the system-generated update function — it takes a sequence of Employee instances with changes — but it only performs the requested updates if they are all legal. To do this, it uses the XQSE iterate-statement to iterate over the incoming Employee instances. If any of them contain a salary change that's too great, it uses fn:error() to throw an exception. If all of the changes turn out to be permissable, it then calls the system-provided update() function on the list of changed Employee instances. Notice that updateChecked() is marked as primary and public, so it is this updateChecked() operation that applications will be able to see and that the system will call when processing updates. (::pragma function <f:function kind="update" visibility="public" isPrimary="true" xmlns:f="urn:annotations.ld.bea.com"/>::) declare procedure tns:updateChecked($changedEmps as changed-element(empl:Employee)*) { iterate $sourceEmp over $changedEmps { if (tns:invalidSalaryChange($sourceEmp)) then fn:error(xs:QName("INVALID_SALARY_CHANGE"), ": Salary change exceeds the limit."); }; tns:update($changedEmps); }; Clear? This is a very important (and common) usage pattern for XQSE, so don't miss the punchline: To override ALDSP's auto-generated update handling logic using XQSE, you can make the system's routine(s) non-primary and instead use XQSE to write new primary create, update, and/or delete operations of your own. You can do all the work yourself in XQSE, or you can — like the example just examined — do whatever special processing you need to do and then turn the rest of the update back over to the system's routine for further processing. Most of the time you will probably want to do that, as it's better from a layered design standpoint. If you let the system finish the job, and someone later changes what it means to "finish the job" at the layer below, what you've done will still work. If you took over everything yourself, you may have to adapt your update logic later when other things change. Before proceeding, you should play around with Employee.ds in Data Services Studio. Try running its various data service operations, including the ones we've just covered. Use one of the read functions to read a set of employees that includes Peter Peon. See what happens if you try to double his salary. Ouch, not this year! At this point, you've seen most of the features of XQSE in action, and you've seen its most common uses. You've seen how to use XQSE to write functions requiring complex, procedural logic; you've seen how to use XQSE to write side-effecting operations, i.e., procedures; and, you've seen how to use XQSE to write custom update logic to augment or replace system-provided updates. At this point you could even roll up your sleeves and write your own updates, deciding that update maps are for wimps, were you so inclined. Surely that must be it — there can't be more to XQSE than that, can there? In fact, there is! Read on... EmployeeBackup.ds: How To Make Bulk XQSEsA class of use case that has come up for data services from time to time is "lightweight ETL". An ETL (or extract, transform, load) system is an enterprise middleware software system that moves data from place to place, such as from operational systems into a data warehouse, usually transforming it from one format into another along the way. High-end ETL systems include features such as seriously high-speed data movement, parallelism, and checkpointing/restartability. Of course, to paraphrase a popular movie quote, with great powers come great list prices — and some ALDSP customers have "small ETL" needs that they wish they could solve without having to buy yet another specialized software package. With XQSE, ALDSP 3 opens the door for using ALDSP for those use cases, i.e., for "lightweight ETL". In this section you will see how that can work. In your copy of the XQSE How-To sample project, you will find a library data service called EmployeeBackup that contains an example. If you open up the design view for EmployeeBackup.ds, you will see that there are three operations on this DS:
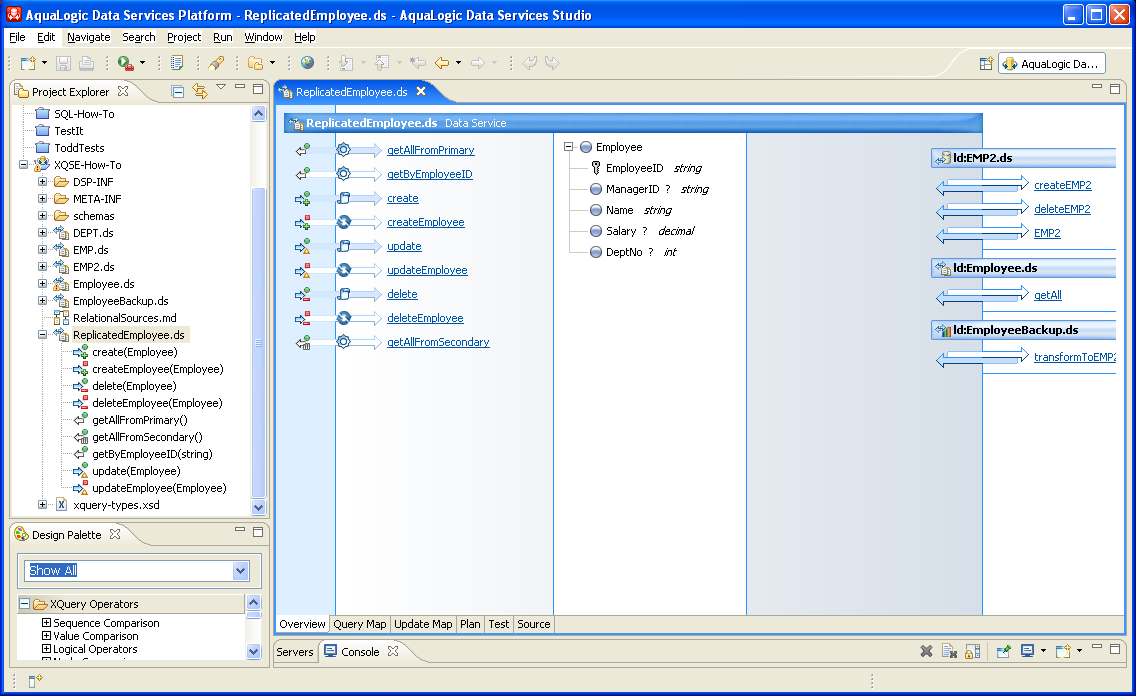
The first operation is another XQuery helper function. Again, XQuery is a part of XQSE, and you will often mix the two when solving your actual use cases, using XQuery whenever possible and XQSE when you need the extra power that it provides. In this case, the XQuery helper function is transformToEMP2(), which takes an Employee instance as input and reshapes it as an instance of EMP2. This function does the "T" part of "ETL" — it transforms its input data into a desired form for use (e.g., loading) elsewhere. The XQuery source code for this function is shown below. Notice how it transforms the data — it parses the incoming name into the multiple parts required by the target, and it does a database lookup to convert the incoming manager ID into the manager name desired by the target. All quite simple, and all something you could tackle without having to make a bunch of excuses! (::pragma function <f:function kind="library" visibility="protected" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com">::) declare function tns:transformToEMP2($emp as element(empl:Employee)?) as element(emp2:EMP2)? { for $emp1 in $emp return <emp2:EMP2> <EmpId>{fn:data($emp1/EmployeeID)}</EmpId> <FirstName>{fn:tokenize(fn:data($emp1/Name),' ')[1]}</FirstName> <LastName>{fn:tokenize(fn:data($emp1/Name),' ')[2]}</LastName> <MgrName>{fn:data(ens1:getByEmployeeID($emp1/ManagerID)/Name)}</MgrName> <Dept>{fn:data($emp1/DeptNo)}</Dept> </emp2:EMP2> }; Lightweight ETL Use Case: copyAllToEMP2Given our little XQuery "T" helper function, we can use the iterate-statement feature of XQSE to do the "E" work — i.e., to extract the desired data from the source system. The same feature can drive the "L" work — the loading — as well. The following procedure, written in XQSE, copies all of the Employee instances from the Employee data service (using its getAll() function) and transforms and inserts them as it goes into the EMP2 DS. It also keeps and returns a count of the number of instances processed as it goes. This is the second operation in EmployeeBackup.ds, and it is called copyAllToEMP2(): (::pragma function <f:function kind="library" visibility="public" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com"/>::) declare procedure tns:copyAllToEMP2() as xs:integer { declare $backupCnt as xs:integer := 0; declare $emp2 as element(emp2:EMP2)?; iterate $emp1 over ens1:getAll() { set $emp2 := tns:transformToEMP2($emp1); emp2:createEMP2($emp2); set $backupCnt := $backupCnt + 1; } return value ($backupCnt); }; Factoid: Because of the relatively simple nature of this iterate loop, this procedure will actually "stream process" the data. That is, given how it's written, it will extract, transform, and then load one datum at a time without needing to materialize all of the data at once. (Nothing fancy, but it will get the job done if the need is accurately characterized by the descriptor "lightweight". In this case, it is.) The third and final operation in EmployeeBackup.ds is deleteAllEMP2(), which uses an XQSE iterate-statement to delete all of the instances in the EMP2 DS: (::pragma function <f:function kind="library" visibility="protected" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com"/>::) declare procedure tns:deleteAllEMP2() as xs:integer{ declare $deleteCnt as xs:integer := 0; iterate $emp2 over emp2:EMP2() { emp2:deleteEMP2($emp2); set $deleteCnt := $deleteCnt + 1; } return value ($deleteCnt); }; This procedure is included simply so you can conveniently play (and then play some more) with this example data service using your copy of the XQSE How-To project. So play! First, use the Test view to explore Employee.ds and EMP2.ds. See what they contain, data-wise. The getAll() function of Employee will show you all the content there, and the EMP2() function of EMP2 will do likewise. EMP2 is initially empty. Now run copyAllToEMP2 and look again. Voila! With ALDSP 3.0, our motto is "Satisfaction guaranteed, or double your data back!" ReplicatedEmployee.ds: How to Make XQSEs for UpdatesYou're almost there! In the final use case, you'll take another look at the pattern of using XQSE to customize updates. You've already seen an example of how to do this, but it's an important enough pattern that it deserves a little extra attention. To make this use case more interesting, you'll also use it to illustrate a bit more about how exception-handling can be done in XQSE by using a try-statement. In this use case, our goal will be to create a ReplicatedEmployee data service. This data service will be a "front" for the Employeee data service, but it will also keep the EMP2 data service in sync by sending any changes (creates, updates, or deletes) that it is notified of to both of those data services. This use case illustrates how XQSE can be used to handle a simple data replication task in real-time rather than via the batch approach employed in the EmployeeBatch example. Note that both batch and incremental replication have their places in the world; our goal here is just to show that (and how!) XQSE can be used to help address such needs if you find yourself facing them in your own use cases. If you open the ReplicatedEmployee data service and switch to its design view, you will see the following:
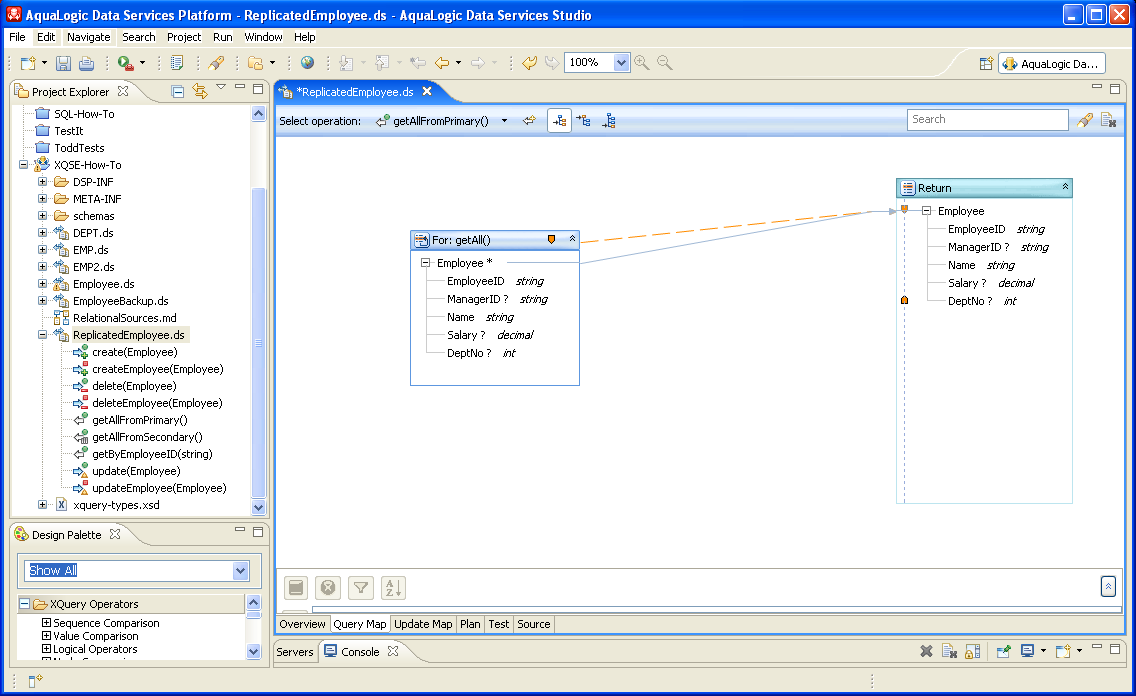
The first function, getAllFromPrimary(), is the primary read function for the ReplicatedEmployee DS. Its definition is exceedingly simple — it just retrieves the contents of the Employee data service for which this data service is a (very thin, in fact) front. Its definition in the Query Map view is the world's simplest graphical query:
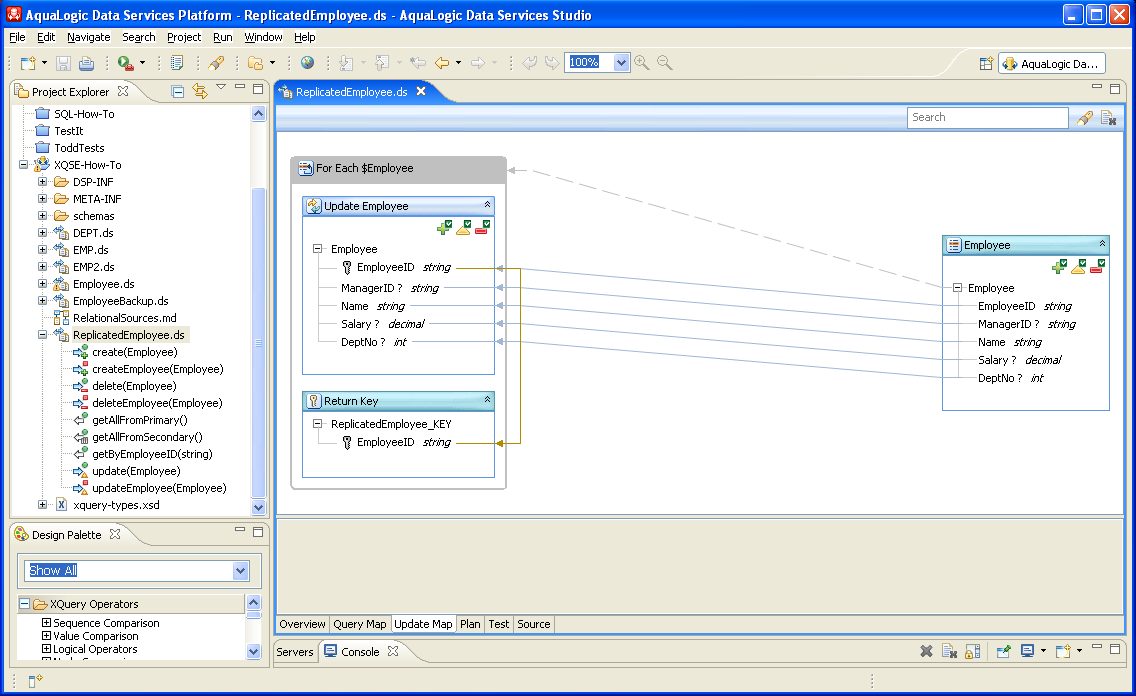
The ReplicatedEmployee data service also has two other functions — getByEmployeeID, which is a simple query over the primary read function with an employee ID value as a parameter, and getAllFromSecondary, which is a library function that we have included so you can inspect the contents of EMP2 without having to switch back and forth between data services all the time in your copy of the XQSE How-To sample project. The resulting source code for all three functions is as follows, for reference: (::pragma function <f:function kind="read" visibility="public" isPrimary="true" xmlns:f="urn:annotations.ld.bea.com">::) declare function tns:getAllFromPrimary() as element(empl:Employee)* { for $Employee in emp1:getAll() return $Employee }; (::pragma function <f:function kind="read" visibility="public" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com">::) declare function tns:getByEmployeeID($id as xs:string?) as element(empl:Employee)? { for $Employee in tns:getAllFromPrimary() where $id eq $Employee/EmployeeID return $Employee }; (::pragma function <f:function kind="library" visibility="public" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com"/>::) declare function tns:getAllFromSecondary() as element(emp2:EMP2)* { for $EMP2 in emp2:EMP2() return $EMP2 }; In addition to these functions, the ReplicatedEmployee data service has six procedures — two create procedures, two update procedures, and two delete procedures. Three of these were generated by asking ALDSP for an update map with C/U/D procedures. These three are the ones you will find named createEmployee(), updateEmployee(), and deleteEmployee(). Their definitions in the source view are: (::pragma function <f:function kind="update" visibility="private" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com"> <nonCacheable/><implementation><updateTemplate/></implementation> </f:function>::) declare procedure tns:updateEmployee($arg as changed-element(empl:Employee)*) as empty() external; (::pragma function <f:function kind="create" visibility="private" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com"> <nonCacheable/><implementation><updateTemplate/></implementation> </f:function>::) declare procedure tns:createEmployee($arg as element(empl:Employee)*) as element(empl:ReplicatedEmployee_KEY)* external; (::pragma function <f:function kind="delete" visibility="private" isPrimary="false" xmlns:f="urn:annotations.ld.bea.com"> <nonCacheable/><implementation><updateTemplate/></implementation> </f:function>::) declare procedure tns:deleteEmployee($arg as element(empl:Employee)*) as empty() external; If you look at the Update Map view for the ReplicatedEmployee DS, you can see how these three procedures came to be and you can infer what they will actually do:
Since the primary read function for this data service reads only from the Employee data service, the system-provided update procedures only propagate changes to the Employee data service. ALDSP has no way of knowing that you want the changes sent to EMP2 as well, so you will have to override the system's update machinery to make that happen. This leads us to the heart of our last use case — the XQSE procedures to accomplish exactly that. As we go, pay attention to the primary/non-primary and public/private annotations on the six update procedures. You will be using the same "trick" here that was used earlier. Namely, you can mark the system-generated procedures as being private and non-primary, use XQSE to write your own update procedures (which call the system-generated ones), and you can mark your new functions as being the public and primary update procedures. By doing so, your procedures become "the" update procedures as far as other consumers of this data service are concerned. Replication Use Case, Part 1: createSo how can you accomplish the desired replication job? Easy. The following source code shows how, with a little bit of XQSE, you can handle creates in a replicated manner. This procedure iterates over the new Employee instances; for each one, it makes a copy (using our earlier transformation function) in the form required for EMP2. It then calls the system-generated createEmployee() procedure to create the new Employee instance and calls EMP2's createEMP2() procedure, passing it the transformed copy, to create the new EMP2 instance as well. Note the use of try/catch here — each call is in an XQSE try-block, and if it fails, the exception is caught in the catch-block. The catch-block logic throws a new exception, indicating to the caller where the failure occurred (primary or secondary copy). Note also the use of fn:concat() to not lose the original cause of the problem. (::pragma function <f:function kind="create" visibility="public" isPrimary="true" xmlns:f="urn:annotations.ld.bea.com"/>::) declare procedure tns:create($newEmps as element(empl:Employee)*) as element(empl:ReplicatedEmployee_KEY)* { iterate $newEmp over $newEmps { declare $newEmp2 as element(emp2:EMP2)? := bns:transformToEMP2($newEmp); try { tns:createEmployee($newEmp); } catch (* into $err, $msg) { fn:error(xs:QName("PRIMARY_CREATE_FAILURE"), fn:concat("Create failed on primary copy due to: ", $err, $msg)); }; try { emp2:createEMP2($newEmp2); } catch (* into $err, $msg) { fn:error(xs:QName("SECONDARY_CREATE_FAILURE"), fn:concat("Create failed on backup copy due to: ", $err, $msg)); }; } }; Clear? To help, in your copy of the XQSE How-To project, play around with this procedure in the test view. Try creating an Employee that already exists and see what happens. For extra credit, you can also play with the underlying Employee and EMP2 data services to cause a variety of failure scenerios. For example, you can manually create or delete an instance in one data service or the other, causing a ReplicatedEmployee create to have a primary key conflict on one, but not both, of the two data services. See if you can cause both primary and secondary create failure exceptions to occur. Replication Use Case, Part 2: deleteTo have have a full replication story, we have to replicate deletes as well as creates, of course. Not a problem — we simply need to invert what we just did in the previous procedure. The following XQSE procedure does just that. Again, it takes a sequence of Employee instances in and iterates over them one by one, making an EMP2 copy of each one and deleting instances from both underlying DSs by using deleteEmployee() on this data service and deleteEMP2() on the EMP2 DS. The same exception-handling pattern is used here as well. (::pragma function <f:function kind="delete" visibility="public" isPrimary="true" xmlns:f="urn:annotations.ld.bea.com"/>::) declare procedure tns:delete($oldEmps as element(empl:Employee)*) { iterate $oldEmp over $oldEmps { declare $oldEmp2 as element(emp2:EMP2)? := bns:transformToEMP2($oldEmp); try { tns:deleteEmployee($oldEmp); } catch (* into $err, $msg) { fn:error(xs:QName("PRIMARY_DELETE_FAILURE"), fn:concat("Delete failed on primary copy due to: ", $err, $msg)); }; try { emp2:deleteEMP2($oldEmp2); } catch (* into $err, $msg) { fn:error(xs:QName("SECONDARY_DELETE_FAILURE"), fn:concat("Delete failed on backup copy due to: ", $err, $msg)); }; } }; Again, stop and play, and again, for extra credit, see if you can cause both primary and delete failures by playing with the underlying data services as well. Replication Use Case, Part 3: updateLast but not least, of course, updates must be replicated as well. We saved the best for last, as updates (instances with changes) are the trickiest to handle, and you will need to think carefully about exactly what your own replication use cases (if/when you face them) need you to do with updates. Here, you will use a similar pattern to the create/delete pattern above, but there's one key difference: As input, you get a list of changed Employee instances. There is no corresponding list of changed EMP2 instances, and (unfortunately) there is no straightforward way to compute one. Thus, you will have to treat the data services asymmetrically. You will propagate the Employee updates to the Employee data service using the system-generated updateEmployee() procedure. However, the corresponding changes to EMP2 will be accomplished by first deleting the old version of each instance and then inserting its desired new version. You can use the fn-bea:old-value() and fn-bea:current-value() functions to get at the desired versions and transform them, which is exactly what we do below: (::pragma function <f:function kind="update" visibility="public" isPrimary="true" xmlns:f="urn:annotations.ld.bea.com"/>::) declare procedure tns:update($changedEmps as changed-element(empl:Employee)*) { iterate $changedEmp over $changedEmps { try { tns:updateEmployee($changedEmp); } catch (* into $err, $msg) { fn:error(xs:QName("PRIMARY_UPDATE_FAILURE"), fn:concat("Update failed on primary copy due to: ", $err, $msg)); }; try { declare $oldEmp as element(empl:Employee)? := fn-bea:old-value($changedEmp); declare $newEmp as element(empl:Employee)? := fn-bea:current-value($changedEmp); declare $oldEmp2 as element(emp2:EMP2)? := bns:transformToEMP2($oldEmp); declare $newEmp2 as element(emp2:EMP2)? := bns:transformToEMP2($newEmp); emp2:deleteEMP2($oldEmp2); emp2:createEMP2($newEmp2); } catch (* into $err, $msg) { fn:error(xs:QName("SECONDARY_UPDATE_FAILURE"), fn:concat("Update failed on backup copy due to: ", $err, $msg)); }; }; }; Again, notice the use of try/catch to flag the reason for any failures. Using Test view, access some ReplicatedEmployee instances, edit them, and save the changes. For extra credit, try inducing failures of various kinds by playing around with the nature of your changes and the data in the underlying sources. Try making a salary change that's bigger than 10% — what happens? Why? Congratulations, You Made It!If you made it to here, you've read all the material, and tried all the suggested exercises, congratulations! You are now officially a "Master of XQSEs". Open up your resume, search for "Programming Languages", and add "XQSE" to the list. You won't see THAT on just anyone's resume! With ALDSP 3.0, you can now use XQSE to accomplish all sorts of things: You can use XQSE to write some very interesting read functions that might have been much tougher in XQuery or possibly not even feasible. You can write procedures in XQSE that encapsulate side-effecting behaviors — things you want clients to do, but only through data service operations that you have written and tested and certified as being ready for prime-time. You can even use XQSE to handle those pesky lightweight ETL tasks that you've faced in the past, this time without having to initiate a six-figure P.O. for yet another enterprise software tool. Last, but by no means least, you can use XQSE in many different ways to customize updates — either by replacing or augmenting the system's automated update handling logic with your own XQSE code. And, no doubt, there are other possibilities as well — things we have yet to imagine (and perhaps would make us cringe if we did... |
| Document generated by Confluence on Apr 28, 2008 16:27 |